How the Website is maintained
Here are some notes on how the website is maintained.
Starting out is the hardest part
Starting a website from scratch is the hardest and slowest parts of having a website. Initially, I have to take into consideration a lot of different things to come up with a design that is functional and serve the purpose. I test out several designs before settling on the final choice. The "theme" has purpose.
When the theme is settled on, things started to fall into place and the first version of the website is published within a short time later.
Once it is started
Once the website is started, changes are a lot simpler because the rest of the web site is already there. Changes do and will occur. New content is added, new information becomes available, new events, event changes, other websites change that are linked to, you name it; a website is never complete. One thing you will never see on my websites is a "under construction" sign. I hate links to pages that are blank, or to pages that say, "Here is where we are going to put stuff about this or about that;" I say if the page has no content, don't waste my time by putting a link to it. Anyway, getting back to the website, ...
When changes have been made on the website source files on my local computer, they need to be re-loaded to the website. That may seem simple enough, but it does get a bit more complex than that.
You may think that I maintain a copy of the website on my computer and the other copy is loaded on the hosting computer servers, and that is all. I wish. First off, I need to plan for all sorts of potential disaster, such as hard disk failures and other computer problems, plus those that are outside my own realm. I have to make constant backup copies (archives) with each major set of changes, and even minor changes if I am not going to be working on the files in the next few minutes. Archives take some time so any time I need to step away from the computer is a good time to start the archive process. I may have as many as 5 or 6 incremental major sets of changes in one day, so 5 or 6 different archives. This might happen because of need to do something else, I was about to be interrupted; I wanted to get something just finished out to the web, or convenience (it was a good stopping place). Often times, the same web page(s) may end up in more than one, or even all of the archives, especially if the same file(s) were being worked on heavily during that day. Occasionally, if I realize that there were no significant incremental changes that would justify having all of the day's individual archives, I might merge them together, overlapping the earlier ones with the later ones. When I have enough collected archives or enough time has passed, copies of the changes are distributed to other locations, just in case. There are actually several "safeguards" to ensure that the original set of files and any changes do not get lost.
The original source files are stored in a repository and are "checked out" when they need to be worked on. Even for my working (development) version, I need to have copies of the repository/website on multiple hard drives just for any bizarre situations (hardware failure, etc.) that affect my local computers. I also need copies in multiple physical locations, just in case of catastrophic natural destruction (fire, floods, tornado, hurricanes, etc.). At any one time, there are copies of the website in different offsite locations, even in different parts of the country (consider the effects of a state wide earthquake). There are even two locations stored outside the country (one in Canada and one in Holland, both accessible to me via computer). O.K., you get the idea.
Cutoff Points are difficult
Once the website is quite stable, when I make a few changes, I can easily decide on a cut-off point, test, and upload the changes. These can be done on a daily basis, or even multiple ones within one day. During major revisions, redesign, re-organizations, or when the website is initially being developed, it is an altogether different story. A cut-off may not be possible for several days, or even weeks, simply because so many things need to be meshed together and be in the right place to make sure everything keeps in sync (still works). Eventually, there are cut-off points where a "new version" can be loaded to the web. Often I get a request to make a simple change to a single web page in the middle of one of these major overhauls. If that website is still evolving (still under development) or going through one of the major overhauls, my working version may not look anything like the one on the web. I have archived off a version that is the same as what is on the web but it is not the same version that I am working on day to day. I may need to make a change to that copy, plus make sure that I reincorporate that change into the set that I have been working on for the next major release. I have to make sure that the change gets made in both places, else the page would change back to the old form when the next generation is uploaded.
Tools help the process but they don't make decisions
Since web page files are plain text, you might think that a simple editor would be all that is needed to create/work on websites. Actually there are a lot of programs used. It has become a necessity in order to adequately maintain large websites, or many smaller websites.
Most websites have a theme, meaning that the design of the website is consistent, such as you can always expect the menu to be on the left side, and it looks the same on all pages. Some parts that are repeated on each page will be maintained in a separate file, and then incorporated into the output for each page. In other cases, the same text is replicated on each page (believe me, there will always be a good reason for why one method is chosen over the other, usually it is related to speed vs. convenience).
A change that affects a common area should be made to all pages. Rather than make the same change repeatedly over and over, software is used to ease the burden. A program that searches and replaces text in multiple files might be used, or in some cases, it may be easier to regenerate a new set of pages. Regenerate a new set of pages? Yes, very often a database specifies the different parts of web pages and a generating program uses the data to create the actual final pages. Some parts of web pages cannot be canned into a database so there are always exceptions. It usually means that part of a page is generated and another text file is added to make the final page. It all depends on what types of changes are needed.
The database/re-generation process is not the only method used to affect common areas of webpages; another method is using server side includes; meaning that on the server where a website is hosted, the common pieces of webpages are contained in separate files, but joined together to form the entire page (by the server software) before the webpage is delivered to the browser. That way, making a change to one file is all that is needed to affect multiple webpages. Because this slows down the delivery slightly, very often a decision is made to maintain a version that already has all of the individual parts. That is why a page might be generated from a database instead.
Changes can be simple or very complex (affecting multiple pages). When you notice a change on the website, you may have no idea what else changed. Depending on what needed to be changed, the changes may have been made manually, or another program was used to change multiple files at once. This is the scary part. Multiple file changes need to be planned well and set up so that multiple files will get the same change but without missing any files, and without screwing anything up in the process. To prevent any disaster, the source files are copied off from the normal development area to a temporary work area so that the true originals are not affected.
When web pages are generated from a database, the database has to be changed, and then re-generate the web pages. Often this is done multiple times until the desired result is achieved. Depending on the database contents, different web page filenames could be generated (different from the last production generation); in these cases, any links to the old name must be changed to the new page name. In some cases, a page is being eliminated intentionally. That means the old pages are no longer needed and will need to be deleted, and in many cases will need to be redirected to the new location (for cases where the original page is being referenced by outside websites so that their links will get visitors back on track).
Regardless of how it is done, the generating programs keep a log of changes, or any errors encountered. Generating web pages means a lot of reading and writing to the disk, which is notoriously the slowest part of a computer. To speed things up, I use a RAM drive (essentially a hard drive but made from RAM memory. Works like a hard drive and way faster than the standard hard drive, but loses its data when the computer is turned off). Since it is a temporary work area, it usually doesn't matter, and it is self-cleaning with a reboot.
When all the changes or page generations are made, the result is looked at to see if it is total garbage or something worth keeping.
If it looks better than the previous set, the output is copied back to the original source files but first, the development environment must be cleaned out, just to make sure that any files that were generated differently (with a different name) from a previous run is no longer going to be there.
There are also potential problems with the software itself. For example, the web page generating program is expecting a clean database. In some cases, a database is provided to me by the client (e.g., a catalog). Hopefully they do not send a bad database (one with unexpected data inside). The web page generating program is actually a collection of programs that process a database to generate web pages. Each 3rd party software program I use has its own quirks and problems, all outside my control. With perfect data, they are flawless. One single character that shouldn't be in the database can cause disaster. I have had cases where special characters in the database caused the generating program to hang and therefore I never get to see the error log to see what might have caused it. Several times, I have had to reboot to terminate the program. Of course, all data on the RAM drive was lost so I have to take a stab at what it was having a problem with, fix it, recopy the source files to the RAM drive, and then run the program again. I have had multiple times where the generating program would hang the computer several times in a row. Of course, when I rebooted, Windows told me that I had not shut my computer down properly and therefore had to scan my hard drive. That takes about an hour because I have drives A through J, M, P, and R. Two drives are 500 Gig so it takes a while to process all the drives.
When the going gets this tough, I switch to using a regular hard drive so that the log file will be there after a reboot. That way, I can get a clue what is causing the problem.
For the majority of the time, things run a lot smoother. After a good run, I look at the error log in more detail, take a look at major pages produced (links to other pages), take a look at the individual pages to see if things look correct, copy the new files back to the development volume (hard drive), and try out a few links. In generated web pages, the number of pages generated is usually quite large so I can't take the time to look at every page individually. In a lot of cases, many pages will be re-generated but exactly as they were before. A comparison of the re-generated pages to a copy of the files before generating will show which files changed, which stayed the same, which files are brand new, and which pages were eliminated. It still doesn't guarantee that the new pages and changed pages will work properly.
If the samples look good, I still need to check to see if any links are broken that I didn't come across with the samples. I run a link check program to test out the entire website. If any links are not working, it will show them to me. This can happen if a field in the database had to be changed but wasn't changed correctly. The link check program also identifies stray files that aren't being used. That is what happens when a web page was created but the link that leads to it is to something else; the old file is now a stray file. The file may no longer be needed but still being generated or it may be correct but the link created is wrong (because of some quirky character in the database).
To keep things running as smoothly as possible, I have my own standards that I go by, rules so to speak. I can roll back a minor change if necessary to make a different change that is desired before the minor change needs to go into effect. I do not roll back major changes however. That means that if a request comes in to make a change, that change may not occur until a major change has completed the production cycle. You need to understand that a request for change can occur at any time, but that does not mean that all change requests can be acted upon within the same amount of response time. A request consisting of "work it in" is quite a bit different from "as soon as possible."
You can see from this that deciding on a breakpoint is not a simple thing. Sometimes, the process itself decides when a new version can be made. In order for me to decide a time for a new version, it requires quite a bit of coordination to ensure that everything will work for that new version when it reaches the web-hosting servers. This is a very important point; if you want me to make a change, or you require me to stop my production cycle for any reason, make sure that you do not treat it as a simple process in the sense that you decide to cancel the request at the last minute. Any time I make a cut-off, stop my computer due to a request to meet, do something extra, or any outside requests, you are requesting a change to my production cycle, and therefore, I hope you will respect my point of view that it should not be a trivial request. In the consulting business, there is no cancellation of a request if it requires me to make changes while still at the computer. In other words, if you request me to stop by to do something, then I will make changes on my end so that I can stop by. When I show up but the request is no longer necessary, the fact that it is no longer necessary does not mean that I should not get paid for being there. If you request me to stop by, I get paid regardless of whether you are ready or not. Keep in mind that a lot of changes had to occur in order for me to stop by. Once you initiate a request, you are committed to some expense.
Which files get sent to the hosting service
The normal development area has lots of extra (stray) files that are used to create the parts that go into the final web pages but are not sent to the hosting service themselves, (i.e., BMP files are used to create JPG files or GIF files but the BMP files are not sent to the hosting service). Even though those files are not loaded to the hosting service, they are very important so the development area will always have strays; the final copy going to the hosting computers should not.
A separate distribution program copies all modified (or new) files (including BMP and other stray files) to a backup location on another drive (just in case I lose the development hard drive, meaning that it fails). Those files are not going to the hosting computers; they are only for my own backup and protection. In a second step, the distribution program copies all modified (or new) files that do eventually get loaded to the host to a local copy (of the web) location (to be used on the web). That program knows to ignore (not copy) files such as BMP files when copying to the local copy location. Now, any extra files in that copy must be as a result of a broken link or a file generated improperly.
The location that has a version of the files that is to be loaded to the web is where I run the link check program. If I ran it on the development volume, there would be too many stray files and I might miss one that should be fixed. When I check in the local copy location, a stray file sticks out like a sore thumb (ideally there should be none in the list of stray files). Every time I do find a problem, I have to go back and find out what caused it, fix it, and re-generate a new set of pages.
Not all files in a website get changed so after I am satisfied with the changes, I don't want to re-load the entire website since that would take an enormously long time, plus it would be sending copies of files that are exactly the same as what is already there. It also is a waste of bandwidth. Instead, I have to make a distribution location of only the files that changed since the last shipment to the web. Source files are copied there only if they have been modified since the last set. Once made, I can ship those files to the web, replacing any older ones, and adding any new ones, except I don't ship to the regular website, instead, I ship to a test location on the web (entirely different servers) for testing purposes.
Even sending files to the web server can have its own set of problems. There can be communication problems, large traffic on the web slowing things down and therefore packets get dropped, ending up with a file that didn't get loaded correctly. Just in case the FTP program fails, I need to make another link check, except this time on the test website itself. Because of changes, there may be stray files that were once used but no longer needed. Those stray files now need to be deleted from the hosting servers so that valuable space is not wasted.
The same files that needed to be deleted on the test website will have to be removed on the production website. Each step must be carried out carefully so as not to break the production website. Because of the human error factor, I can make mistakes. I have broken a website by accidentally deleting the wrong file; granted that has happened only a few times but it has happened. Thankfully, I have my link checker program that can find those accidents. The link checker program takes a lot of time because I use it to check all websites I work on so even though it can find that a link is broken, I may not get through the entire report until visitors to the website have already encountered the problem; those are the bad times I wish I could crawl under a rock.
The links check program can identify strays (orphans) on my local drives but not on the server. As a result, when strays are identified on the local computer, those same names must be retained so that the same ones can be deleted from the hosting servers.
The link check tells me about missing files on the server caused by moving a source file to a new location. For example, if I decide to move where a file is on the local copy, I have to do the same on the web, except the file was copied or moved locally but the file modification date never changed because the file contents were not actually changed. The step that copies based on files modified since last sending to the web will not copy those moved/renamed files. When copying locally, I can check against the target files. When getting ready to ship to the web, the program doesn't have anything to check against so I copy files modified within a certain number of hours. If I don't start that operation just perfectly (to the minute of an hour when the last run occurred), I need to add an hour. Even if I am lucky that the exact minute is about to happen, if I kick the command off on the dot, it will still take more than a minute to complete so some changes might get missed; to be safe I have to add an hour. If I did a lot of changes within that very last hour before starting a new cutoff point, a lot of files will be sent that were sent the last time; in other words, they are exact duplicates of what is already there.
When the test website works as expected and I have a list of every unmodified file that needs to be sent to its new location, then I can send that set to the production website without a great deal of stress that it will break the working website.
I still need to check the production website to ensure all links work correctly just in case the FTP program failed to send a file correctly (which can happen due to poor communications, dropped communication lines, high web traffic, or FTP program defects), or even for the human error factor.
Even when no changes need to be made, every so often, the link checking software needs to be run to ensure that links to other websites still work as they originally did. Even when they fail, it may be because their website host was temporarily not available, or due to high traffic, simply not accessible. Each error must be interrogated independently. If a link fails when testing manually, I have to see if the link was to the start of the website or to a specific page (deep linking). If it is to a specific page, it may fail because the website is being reorganized or it may fail because the entire website is down. The link may not fail in another hour, or if it does, it may not fail the next day. Only when I am sure that the website has changed permanently (or has closed) do I actually make a change on my end. If a reasonable period has passed and the link still fails, then I remove the link but save the information because it still might come back. There are numerous cases where a link was not available for several days, several weeks, even several months, then re-appear just like it was originally. If our link was to an important site, then we would like to keep it. Checking it again later on may mean that we can put it back. This means I have to keep an extra page with deleted links so I can check again in the future.
Likewise, we (as a website) have a responsibility too. Other websites may have a link to us. If I decide I really need to move a web page to a new location or need to change its name, I need to be sure that I am not breaking someone else's website. It is difficult to locate all websites that have a link to us. If it is a large website that has been indexed by the major searchengines, then it may be possible to find out about the link to us; for smaller websites, it may not be possible. Therefore, when I move or rename a web page, I will keep a page in the original location to redirect users to the new location. Then I need to check the web traffic to see if anyone ever uses the old web page. If I can find out that it came from a specific website, then I may be able to contact the owner and request they update their website.
As human as you are
I also am human and I do make mistakes. I am lucky to have ancestors that corrected my English; those early pushes were enough to make me pursue writing skills. I am an excellent speller most days but some days a word doesn't come out right, or it doesn't look right, even simple words. Regardless of what day it is, I am not a perfect typist. A crash course in typing (when I cracked an ankle in the military that forced me to work in the office), plus many years at a computer keyboard has helped; but I still make mistakes. I get by with spellcheck programs for the most part, but a rush sometimes causes me to forget. At this point in time, spellchecking is not a built in and automatic feature to file maintenance. Wouldn't it be nice if there were a way to tell whether a file has had spellcheck run on it or not since it has been modified, or to do it automatically? There is a wide range of HTML editors, some have spellcheck, and some don't. The other programs I use don't do spellcheck unless I remember to do it myself. As a result, I am very often re-checking pages that have already been spellchecked, or worst yet, not remembering to perform spellcheck on a page. I occasionally find a page with a spelling error that has been there for a long time. Therefore, if you spot one, it will not hurt my feeling if you tell me. I had rather you tell me than to let the rest of the world see it too.
The rules keep changing
If all that weren't enough, the Internet is a constantly changing technology and that means that how we did things a few years ago are no longer the correct way to do things today. The HTML standard keeps advancing; new features are introduced and old methods are deprecated (phased out). As browser support for new features are incorporated, then we can add the same to the web pages. Likewise, as browsers drop support for old methods, we must remove those same methods from our website. Even though I might add a new feature, it does not mean that all users will be able to take advantage of it. I add it if it has benefit to some users. For example, the largest number of users is using Internet Explorer as their browser. Therefore, if Internet Explorer starts supporting a new feature, it might be added to our website, as long as it does not interfere with what others will see. Others may not be able to take advantage of the new feature but they will not be deprived of the content we intend to show.
| Browser Usage Stats (as of August 2004) (use with caution) | |||||
|---|---|---|---|---|---|
| IE6 (windows) | 73% | 76% | 65% | 76% | 51% |
| IE5 (windows) | 12% | 9.6% | 20% | 18% | 12% |
| IE5 (Mac) | 1.2% | ||||
| IE4 (windows) | .15% | .1% | 1.2% | .35% | 1.0% |
| KHTML based | 1.5% | 1.5% | 1.1% | ? | ? |
| Gecko based | 3.0% | 8.7% | 4.4% | 1.1% | 21% |
| NN4 | 1.4% | .55% | 1.4% | .3% | 1.1% |
| Opera | .35% | 1.6% | .4% | .55% | .85% |
| other | .4% | .3% | .6% | ||
| unidentified | 8.6% | 6.6% | 3.1% | 12% | |
The three charts below show a snapshot taken on March 16, 2004 based on 1000 visitors as tabulated by three statistics gathering companies (eXTReMe, CQ, and OneStat). Both Netscape 7 and Mozilla are built on the same underlying software. It looks like eXTReMe counts both as "Netscape 7", while CQ counter includes Mozilla in the "other" category.
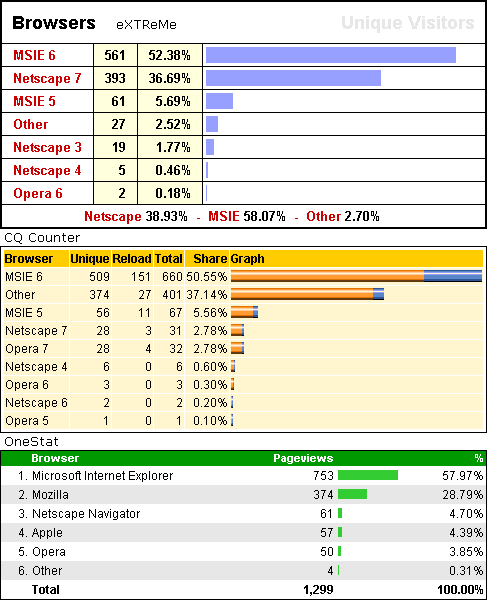
As you can see, Internet Explorer is the leading browser in use. Even though the figures are constantly changing, it will take a while before any other browser outranks Internet Explorer. These figures are monitored and even though the charts are not current for today, they are close enough to make the point. We develop for the majority first. If something doesn't work for one user but works for another, then very likely it is because the one that it did not work for is using a browser in the minority. Since their friends also use the same browser, they have the impression that they are using the most popular browser. Very often their knowledge of the true statistics does not exist. As a rule, this rarely ever happens because I develop websites using standards set by the W3C organization, the page are in turn validated, so if someone has a problem, it most likely will be their browser or their setup, not because I did something that leaves them out.
Nothing "flashy"
Depending on the audience, different features and methods can be implemented. For example, a technology that allows multiple pages to be displayed at the same time to the user seamlessly is called "Frames." Most new browsers support Frames perfectly but it wasn't always that way. Early implementers of websites that used Frames lost viewers due to the viewer's browser not supporting the technology. Users come in all ages, all backgrounds, and all amounts of disposable income. Younger audiences have the latest browsers but older citizens do not necessarily have the latest computers or latest browsers. They have the "hand-me-downs" from their yuppie children, since they only want to get online to check their e-mail, but invariably, they can't help surfing the net, or clicking on a link that someone sent them in the mail. If those users visit our website but they can't see anything because our website uses technologies such as Frames, we might be losing the very audience that we are attempting to appeal to. I'm sure a lot of our viewers do not have the latest browsers so I keep that in mind with any new development.
Some technologies require a browser plug-in to work. Websites that use a technology called Flash may look dazzling, but if the user doesn't have the latest plug-in, they might not be able to enjoy it, and many may not even understand how to get the latest Flash plug-in. The same goes for all types of multimedia. If we get too fancy with the technology, we will frustrate our biggest audience.
For these reasons, I try to not go overboard with new technologies, and have made a conscious effort to keep the technology used in sync with the widest range of viewers. I hope you appreciate why the website is the way that it is, and understand why we don't have a lot of "Flash!"
Photos and Image sizes
A web site is never really done. Just like required changes, there are new bits of information that requires an entirely different page, or even an entire section. A shell of a page can be used when starting a new page but the content must be inserted. Adding text is simple enough, but what about photos?
Photos come to me in one of two forms; either printed photos or digital versions. The paper versions need to be scanned in, then manipulated for use on the website. Today's scanners have amazing statistics of resolution and the number of bits used to store the color for each pixel. In spite of the high resolution advertised, usually the high resolution is through an interpretive mathematical formation of the actual "true" resolution of the scanner. The scanner I use can scan at resolutions of up to 4800 pixels per inch, but if it is set to greater than 200 pixels per inch, it warns you that no greater quality image will result since 200 pixels is the true resolution of the scanner, plus that using higher settings will result in way larger file sizes. The end result large image will have lots of "interpretive" bits created by looking at the surrounding pixels. Those extra pixels are meaningless unless the image was going to be used on an ultra-high resolution printer, where a 200 pixel per inch image would cause the image to be printed too small. A computer's screen typically has a resolution of 72 or 96 pixels per inch. In other words, a 200 pixel per inch scanner will work excellent for web publishing. It is important to note that image files not only have a horizontal and vertical number of pixels, but also have a dots-per-inch for the image. A 300 dots-per-inch image is wasted on the computer screen but would be very important if the file were to be printed using a printer, which most likely has the ability to print at over 300 dots-per-inch.
For a scanner resolution of 200 pixels per inch, a 4x6 print should end up being 1200x800 pixels. For an entire roll of 4x6 prints, each scanned image will have a slightly different number of pixels instead of the ideal and consistent 1200x800 pixels. Scanners usually have an auto-detect size mode, pretty consistent but never exactly the same over the entire roll. Adjusting the size to be the same will end up with some photos having extra white space, and some having portions of the photo cut off, depending on where the adjustment cutoff is made. I usually let the scanner make the first guess, then tweak it to ensure no photo portion is cut off.
Generally the intent is to have the photos all be the same exact size. First, I have to "trim" any non-photo portions (white space at edge) that end up in the scanned version. If the entire set can handle the same amount of cropping without losing any details at the edges (being cropped off), then it is easier to trim all photos the same way. Sometimes, it is easier to trim each one selectively, and then resize each photo to be the same size as a master choice (e.g., 1200x800).
A 1200x800 pixel image is a good size to end up with. The image will work well for users with very large computer screens, and exactly half that size (600x400) will work for the majority of users, and a preview can be made by sizing down to any one of several smaller sizes.
The quality of the end result can be affected quite a bit by the type of file that was used for the photo, the lighting conditions, the condition of the camera, and the ability of the photographer. Very often what appears to be a great photo print will not fair well when converted to a digital photo. A great professional photographer using a high-quality camera, under ideal lighting conditions, cannot make a poor choice of film look good. Especially when photographing for the web or computer screen (meaning a photo that will need to be scanned), use a good high-quality film. The extra money you spend on film will show up on the computer screen.
Digital Cameras make an impact
The digital versions of photos received only eliminate the first steps that deal with the scanner and resizing all to be the same. Digital photos from the same camera are always the same size, although there are a great variety of sizes out there due to the diversity of camera manufacturers, and capture devices used in digital cameras.
If the digital images are of high enough quality, then they are much more likely to be used on the web, provided the content is good, the image is needed, etc.
Digital cameras have their own set of problems. Very often the images are not of high enough quality to use on the web. Why not? Lack of knowledge and economics are basically the answer, however it does go much deeper than that. Lack of knowledge can only take 10% of the blame; economics affects the rest.
Lack of knowledge means we make poor purchase decisions but the digital camera manufacturers also play an important role in the purchase decision and available choices.
We are in the phase where everyone wants a digital camera so the prices are upped by the high demand, but we don't want to spend any more than we have to. Digital camera manufacturers are in an ever-changing technology area; they try the latest electronics for a model or two, and then go on to the next design using newer technology. Their camera models are based on the image capture devices that they either manufacturer themselves, or purchase from electronics manufacturers. Based on supplied technical specifications, they know which devices do a better job, and those devices cost more money. To stay in business, they also know that their camera models need to fit all ranges of pocketbooks, and I don't mean fit in size, I mean in economics.
Cameras get manufactured in cycles, each stage an improvement over the last. As soon as a new camera model comes out, the last batch is "inferior" to the latest set. Consider the notion that all of their cameras get sold eventually. If less than 10% of their models are the top-of-the-line, then less then 10% of the cameras worldwide are top-of-the-line for any given point in time. Add to that that most of the earliest digital cameras are still out there, and newer models keep coming out, therefore a smaller percentage of the digital cameras taking pictures are top-of-the-line. In time, this will stabilize as the earliest cameras get left on the shelf in lieu of a newer model. Still, there will be only a small percentage of top-of-the-line cameras taking pictures.
A lot of people have purchased poor quality digital cameras; if less than 10% are top-of-the-line, then 90% of digital cameras are not producing the best images. Don't feel bad for having less than the top-of-the-line digital camera; think of it as being like 90% of the rest of the world.
You can blame some the purchase decisions on lack of knowledge, but it doesn't cover all explanations. In addition to the manufacturer's role, and partly because of it, we make a lot of poor purchase decisions, some forced by economics. Sometimes, even with the extra knowledge, our budget doesn't allow the better camera so we settle for something below the one we originally wanted. Even with nearly unlimited funds, we can still make a poor decision. We can be influenced by a good ad, a good review, or a personal or even professional recommendation. Regardless of any external input, nothing beats seeing the end result, compared to similar priced cameras. Most likely you aren't going to "buy them all" and decide which one to keep. When I started on this endeavor in 2000, I located a website that allowed the user to compare the resultant images of two different cameras side by side on the same screen. That website changed my opinion on what I thought would have been a great camera. Several great reviews had convinced me that a Fuji digital was a great purchase, but when the end result images were compared next to another great reviewed camera (Nikon 990), the Nikon was the overly obvious better choice. Even for more money, it was clear that anything less would be a disappointment. Since my researach, there have been a lot more digitial camera models produced, and due to the large growth, keeping the compare website up to date has been a great expense. They no longer have every model included in their database. Now you may donate to the website to see what models they do list. Check out "The Comparometer".
Now that you know the background of why that digital cameras have their own set of issues, it is not a reason to NOT send your digital photos. Even with the "bottom-of-the-line" digital cameras, great pictures can come out of the them.
One of the problems of high quality digital images is getting them to me. The most common form is e-mail but high quality photo images have a larger file size, and very often the e-mail being used to send a photo has a limit on the amount of data that was sent.
Photos require a lot of processing from what is started out with. If I start out with a great photo, then it certainly makes the rest of the work easier. Still, the photo will have an inspection. In some cases it fails totally and cannot be used due to poor quality (poor color, too dark, cropped poorly, not enough image, etc.) but what if it is the only thing we have and we definitely need the photo. That has happened.
Photos often need color corrections, contrast corrections, cropping, rotating to be level, and all sorts of other alterations. The photos need to load fast and look decent. One consideration is image size on the screen. How much real estate it will take up depends on the resolution of the user's screen, something I have no control over. I can detect the resolution of the computer screen of the user but I do not know how much of it is being used for the browser; I can only presume that they are using the full size, or that they should use the full size to get the best viewing.
An image that might look fine for one person may look so small for another that they can hardly see it. In some cases, I need to maintain multiple sizes of the same image and load the one that would work best for the user based on their resolution setting. In many cases, having a small version for preview, and then an enlarged view solves most of the problem; at least for now. As computer screens get higher and higher in resolution, and the computing power is there to back it up, our images will seem smaller and smaller. At some point in the future, we will need to take new digital photos with more pixels, or re-scan the paper copies with the new scanners that will be out then.
In the meantime, once the image size(s) is chosen, and the image quality work finished, the image needs to be compressed as much as possible without losing quality. Depending on what the image consists of, the end result needs to have the right size (pixels for width and height), the right amount of dots per inch (for the screen), and the file could be in one of several file formats.
There is a lot of work that goes into each photograph. For each web page that has a photo, about ten times as much time is spent on the image as spent on the rest of the page.
Writing for the future
While composing the actual text of a webpage, special consideration has to be made to ensure that the text is not written from a point of reference that will be incorrect in the future. For example, reference to something that happened "last month" will be incorrect the next month. Also, text that announces a future event will be incorrect after the date has passed. An event page lists event details in a manner that the text will not need to be edited following the event. Other portions of the website is different though. For example, text that announces a special upcoming event would be incorrect following the event. For this reason, some parts of our website is automated to display different text depending on the date or the time that the visitor sees the page. In writing text for the future, you may wonder how do I test things out to see how it will appear. Very simply, I slip into my time machine, slip ahead a bit, do some testing, then slip back before anyone notices (usually late at night). Actually, it is simpler than that. I double-click on the time display in the system tray, and then change the date forward (or backward even) but I do not click on Apply. Then I return to the page that I want to test and "Refresh the page." Voila! Different text. If everything is worded as I want it to appear in the future, then I switch back to the clock properties and click on Cancel. What is wonderful about this is that you do not have to commit to the new date changes to have the system use the new date. However, this only applies to the date, not when changing the time only. A different time will be used as long as I also change the date. This method of testing for the future does not work on all operating systems. I have to make sure I test these situations under the right conditions.
Conclusion
There are lots of other considerations that affect ongoing website maintenance but I think you get the idea that even what would seemingly be a simple task can turn into much more. And you thought it was all very simple, right? Now, let me leave you with one final thought about what I do.
What I Do
There are times that I get out and times that I remain in front of the computer for long hours. There are many work days that consists of working at the computer for as long as 18 hours a day. During that time I will get up to eat, and do the normal necessities of life, but most of the time will be spent in front of the computer. Since I work on multiple projects, I have to keep track of the times worked on each. It makes it easier to stick with one project for a longer period of time than to switch back and forth. I don't always work 18 hour days however, and there are stretches where the most I get in front of the computer is around 12 hours a day, and occasionally down to a normal 8 (rare). But if I don't have anything else to do, most likely I will be in front of the computer. The extreme 18 hours days can occur in stretches of a week at a time or more. Stretches of 18 hour days are usually in a time of crisis to finish a piece of work by a deadline, or because I really didn't have anything else to do that required me stepping away. If you find this bizarre, I understand because, when I first started working on the computer, I too found it odd that time can really get away from you when in "terminal land."* Having time fly by when using a computer came in handy during my extreme consulting years where you get paid by the hour. During my longest week, I worked 112.25 hours.*
Keeping up with technology changes
All my time is not spent working on one thing. I have multiple projects to work on, plus it is a constant battle to "keep up" with technology. I take online classes/courses, attend online seminars, and try out the new technology and tools. All of this is a joy to me. I like what I do. I hope you can tell.
If you read the entire page, say so by sending me e-mail. And thank you for your curiosity to read it.
If you have any questions regarding our guarantee, please contact Customer Service.
Also Read
| Intro | Introduction to Web Development Services | |
| Why | Why you need a web page. | |
| Stats | This should scare you (at least back then it did). | |
| Prices | Packages, Prices, Options | |
| Extras | Extras Prices (with Descriptions) | |
| Additional Services | FTP, Link Maintenance, Webmaster, Proofread, Backup, Restore | |
| Domain Name Registering | Web Hosting | e-mail Hosting | Websites Explained | ||
| Web Development Terms & Conditions | Web Development Guarantee | Web Development Disclaimer | ||
| US Copyright Office | Copyright Basics | 10 Copyright Myths | ||
Web Development Services taken on a First-Come-First-Served basis!